Ce sont deux mesures différentes pour évaluer les performances de votre modèle, généralement utilisées dans différentes phases.
La perte est souvent utilisée dans le processus de formation pour trouver les «meilleures» valeurs de paramètres pour votre modèle (par exemple, les poids dans le réseau neuronal). C'est ce que vous essayez d'optimiser dans la formation en mettant à jour les poids.
La précision est plus d'un point de vue appliqué. Une fois que vous avez trouvé les paramètres optimisés ci-dessus, vous utilisez ces métriques pour évaluer la précision de la prévision de votre modèle par rapport aux vraies données.
Prenons un exemple de classification des jouets. Vous voulez prédire le sexe à partir de son poids et de sa taille. Vous avez 3 données, elles sont les suivantes: (0 signifie homme, 1 signifie femme)
y1 = 0, x1_w = 50kg, x2_h = 160cm;
y2 = 0, x2_w = 60kg, x2_h = 170cm;
y3 = 1, x3_w = 55 kg, x3_h = 175 cm;
Vous utilisez un modèle de régression logistique simple qui est y = 1 / (1 + exp- (b1 * x_w + b2 * x_h))
Comment trouvez-vous b1 et b2? vous définissez d'abord une perte et utilisez une méthode d'optimisation pour minimiser la perte de manière itérative en mettant à jour b1 et b2.
Dans notre exemple, une perte typique pour ce problème de classification binaire peut être: (un signe moins doit être ajouté devant le signe de sommation)

Nous ne savons pas ce que devraient être b1 et b2. Supposons au hasard que b1 = 0,1 et b2 = -0,03. Alors quelle est notre perte maintenant?
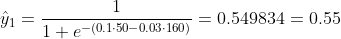
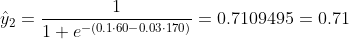
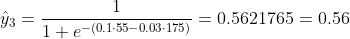
donc la perte est
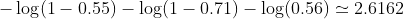
Ensuite, votre algorithme d'apprentissage (par exemple la descente de gradient) trouvera un moyen de mettre à jour b1 et b2 pour diminuer la perte.
Et si b1 = 0,1 et b2 = -0,03 sont les b1 et b2 finaux (sortie de la descente de gradient), quelle est la précision maintenant?
Supposons que si y_hat> = 0,5, nous décidons que notre prédiction est féminine (1). sinon, ce serait 0. Par conséquent, notre algorithme prédit y1 = 1, y2 = 1 et y3 = 1. Quelle est notre précision? Nous faisons une mauvaise prédiction sur y1 et y2 et faisons une bonne sur y3. Alors maintenant, notre précision est de 1/3 = 33,33%
PS: Dans la réponse d'Amir, la rétropropagation serait une méthode d'optimisation en NN. Je pense que ce serait traité comme un moyen de trouver un gradient pour les poids en NN. La méthode d'optimisation commune dans NN est GradientDescent et Adam.
