J'ai cette question depuis des mois. Il semble que nous venons de deviner intelligemment le softmax comme une fonction de sortie, puis d'interpréter l'entrée du softmax comme des probabilités log. Comme vous l'avez dit, pourquoi ne pas simplement normaliser tous les extrants en les divisant par leur somme? J'ai trouvé la réponse dans le livre Deep Learning de Goodfellow, Bengio et Courville (2016) dans la section 6.2.2.
Disons que notre dernière couche cachée nous donne z comme activation. Ensuite, le softmax est défini comme

Explication très courte
L'exp dans la fonction softmax annule grossièrement le log de la perte d'entropie croisée, ce qui fait que la perte est à peu près linéaire dans z_i. Cela conduit à un gradient à peu près constant, lorsque le modèle est erroné, lui permettant de se corriger rapidement. Ainsi, un softmax saturé incorrect ne provoque pas de gradient de fuite.
Brève explication
La méthode la plus populaire pour former un réseau de neurones est l'estimation du maximum de vraisemblance. Nous estimons les paramètres thêta de manière à maximiser la probabilité des données d'apprentissage (de taille m). Étant donné que la probabilité de l'ensemble de données d'apprentissage est un produit des probabilités de chaque échantillon, il est plus facile de maximiser la log-vraisemblance de l'ensemble de données et donc la somme de la log-vraisemblance de chaque échantillon indexé par k:
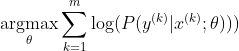
Maintenant, nous nous concentrons uniquement sur le softmax ici avec z déjà donné, nous pouvons donc remplacer
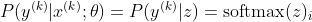
avec i étant la classe correcte du kème échantillon. Maintenant, nous voyons que lorsque nous prenons le logarithme du softmax, pour calculer la log-vraisemblance de l'échantillon, nous obtenons:
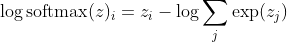
, qui pour de grandes différences de z se rapproche approximativement de
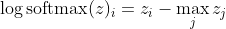
Tout d'abord, nous voyons ici la composante linéaire z_i. Deuxièmement, nous pouvons examiner le comportement de max (z) pour deux cas:
- Si le modèle est correct, alors max (z) sera z_i. Ainsi, la log-vraisemblance asymptote zéro (c'est-à-dire une probabilité de 1) avec une différence croissante entre z_i et les autres entrées de z.
- Si le modèle est incorrect, alors max (z) sera un autre z_j> z_i. Ainsi, l'ajout de z_i n'annule pas complètement -z_j et la log-vraisemblance est approximativement (z_i - z_j). Cela indique clairement au modèle ce qu'il faut faire pour augmenter la log-vraisemblance: augmenter z_i et diminuer z_j.
Nous voyons que la log-vraisemblance globale sera dominée par les échantillons, où le modèle est incorrect. Aussi, même si le modèle est vraiment incorrect, ce qui conduit à un softmax saturé, la fonction de perte ne sature pas. Il est approximativement linéaire dans z_j, ce qui signifie que nous avons un gradient à peu près constant. Cela permet au modèle de se corriger rapidement. Notez que ce n'est pas le cas pour l'erreur quadratique moyenne par exemple.
Explication longue
Si le softmax vous semble toujours être un choix arbitraire, vous pouvez jeter un œil à la justification de l'utilisation du sigmoïde dans la régression logistique:
Pourquoi la fonction sigmoïde au lieu de toute autre chose?
Le softmax est la généralisation du sigmoïde pour des problèmes multi-classes justifiés de manière analogue.



