Ken a déjà résumé certaines des raisons dans sa réponse . Pour approfondir cela
- Plus de cache , plus rapide que la RAM
De toute évidence, les caches plus grandes nécessitent plus de transistors. Mais avec plus de transistors, nous avons également le choix d'utiliser des caches plus rapides . Les caches CPU ne sont que de la SRAM qui est généralement constituée de 6 transistors (AKA 6T SRAM). Cependant, quand il y a suffisamment de transistors, il peut être utile d'utiliser des cellules SRAM plus rapides mais plus grandes constituées de plus de 6 transistors (tels que 8T, 10T SRAM)
- Plus d' instructions SIMD , qui traitent plus rapidement que les instructions à données uniques
Non seulement SIMD mais tout type d'instructions d'accélération. Par exemple, les architectures modernes ont souvent une unité AES pour un chiffrement / déchiffrement plus rapide, un FMA pour un meilleur calcul mathématique (en particulier le traitement numérique du signal) ou une virtualisation pour des machines virtuelles plus rapides. La prise en charge de plus d'instructions signifie que davantage de ressources sont nécessaires pour les décoder et les exécuter
- Plus de cœurs , vous pouvez donc faire deux ou plusieurs choses à la fois
- Pipelines , pour que chaque cœur puisse faire plus de choses à la fois
Ce sont assez clairs
- Unités fonctionnelles, comme intégré FPU s et plusieurs ALU s
Dans le passé, il n'y avait pas assez de zone de matrice pour le FPU, donc les gens doivent en acheter un autre s'ils ont des exigences élevées en arithmétique à virgule flottante. Avec beaucoup plus de transistors, il est possible d'avoir le FPU intégré, ce qui accélère beaucoup les mathématiques en virgule flottante
De plus, les processeurs modernes sont superscalaires et essaieront de faire plusieurs choses à la fois en trouvant des données indépendantes et en les calculant plus tôt, même si le flux d'instructions est linéaire et série. Plus ils peuvent faire de choses en parallèle, plus ils seront rapides. Pour ce faire, une CPU peut avoir plusieurs ALU et une ALU peut avoir plusieurs unités d'exécution. Si, par exemple, un processeur a 5 additionneurs contre 4 dans la génération précédente, il fonctionne déjà 25% plus rapidement dans la situation la plus optimiste sans aucun changement d'horloge. Les processeurs plus sophistiqués utilisent même une exécution dans le désordre (ce qui est le cas pour la plupart des processeurs hautes performances modernes)
Les opérations peuvent généralement être effectuées de différentes manières. Si vous avez plus de transistors, vous aurez plus de ressources pour utiliser une technique plus rapide. Quelques exemples simples:
Décalage de bits:
Un changement de vitesse simple est réalisé en connectant les tongs en série.

Cela ne nécessite qu'une seule bascule par bit, donc extrêmement compact. Mais il a besoin d'une horloge pour décaler d'un bit vers la gauche ou la droite. C'est pourquoi les microcontrôleurs et les petits processeurs intégrés n'ont que des instructions pour passer d'une unité. Voir
Lorsque vous avez plus de transistors à dépenser, vous pouvez changer de barillet . Désormais, un processeur peut décaler des bits en une seule horloge avec le coût de centaines ou de milliers de transistors
Une addition:
- Un simple additionneur est également réalisé en connectant des additionneurs complets en série. De cette façon, un additionneur de N bits a besoin de N horloges pour terminer son travail, ce qui n'est certainement pas ce que les gens attendent d'un CPU
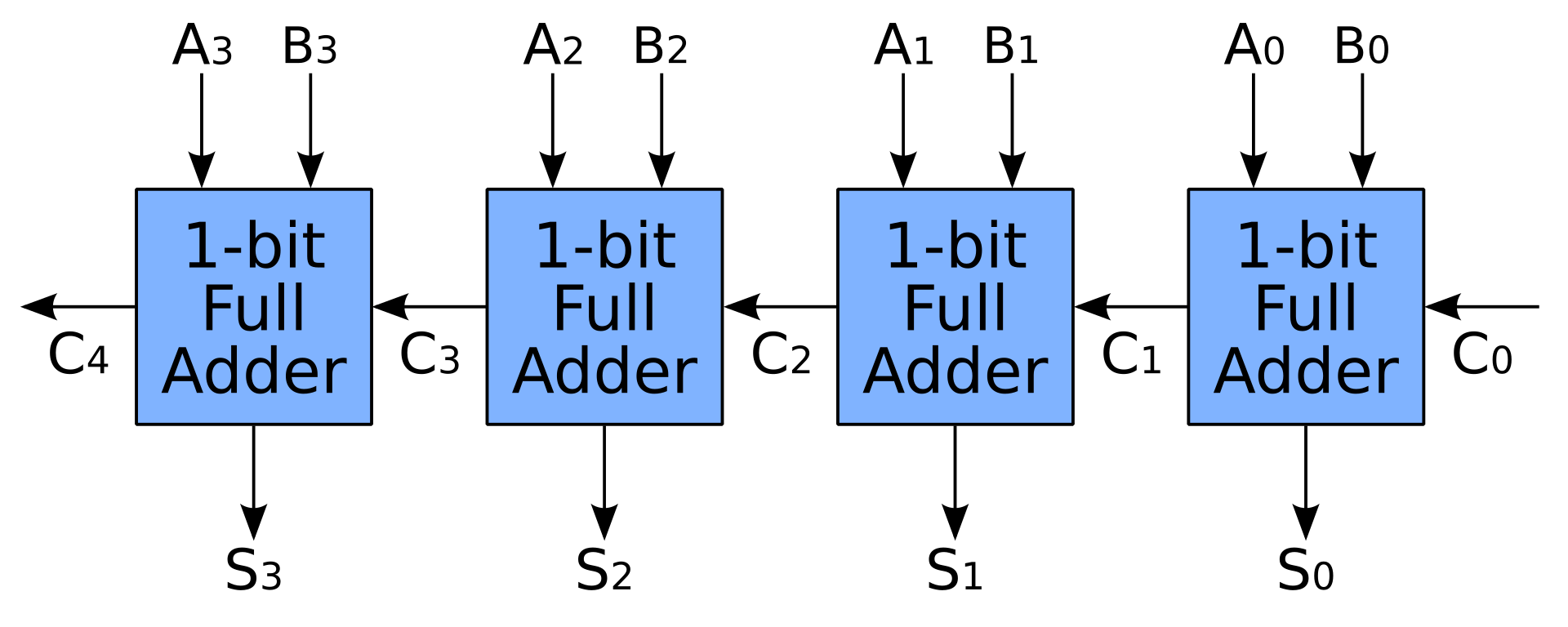
- Avec plus de transistors, nous pouvons accélérer l'addition en pré-calculant les portages avec un report d'anticipation ou un report de sauvegarde . Les additionneurs complets sont toujours utilisés, mais beaucoup plus d'espace est nécessaire pour l'unité de précalculage
La même chose s'applique à d'autres unités comme les multiplicateurs, les diviseurs, l'ordonnanceur ... Par exemple, nous pouvons faire une multiplication extrêmement rapide en une seule horloge en utilisant la logique combinatoire . Vous pouvez voir quelques exemples simples dans la question multiplicateurs 3 bits - comment fonctionnent-ils? . Mais les transistors nécessaires se développeront au carré des largeurs d'entrée, donc les petits processeurs avec un multiplicateur utilisent une logique séquentielle à la place pour économiser beaucoup d'espace pour le multiplicateur:
Les anciennes architectures à multiplicateurs employaient un levier de vitesses et un accumulateur pour additionner chaque produit partiel, souvent un produit partiel par cycle, en échangeant la vitesse contre la zone de la filière. Les architectures de multiplicateurs modernes utilisent l'algorithme de Baugh-Wooley (modifié), les arbres de Wallace ou les multiplicateurs de Dadda pour additionner les produits partiels en un seul cycle. Les performances de l'implémentation de l'arborescence Wallace sont parfois améliorées par le codage Booth modifié de l'un des deux multiplicands, ce qui réduit le nombre de produits partiels à additionner
https://en.wikipedia.org/wiki/Binary_multiplier#Implementations
Une fois que vous avez un énorme pool de transistors, vous pouvez même utiliser la logique combinatoire pour faire un FMA qui est beaucoup plus gourmand en ressources qu'un multiplicateur
Les ordinateurs modernes peuvent contenir un MAC dédié, composé d'un multiplicateur implémenté en logique combinatoire suivi d'un additionneur et d'un registre accumulateur qui stocke le résultat. La sortie du registre est renvoyée à une entrée de l'additionneur, de sorte qu'à chaque cycle d'horloge, la sortie du multiplicateur est ajoutée au registre. Les multiplicateurs multinationaux nécessitent une grande quantité de logique, mais peuvent calculer un produit beaucoup plus rapidement que la méthode de décalage et d'ajout typique des ordinateurs précédents.
Opération de multiplication – accumulation

#/media/File:1-bit_full-adder.svg)