Pour chaque utilisateur, vous avez deux séries temporelles, lat (t) et longue (t). Je pense que c'est la représentation la plus simple - je n'essaierais pas de compliquer les choses en me convertissant à une certaine définition des virages, ce qui serait non seulement plus difficile, mais nécessiterait également d'être très prudent sur le point de départ initial et de le traiter différemment dans tout une analyse. (C'est probablement aussi plus bruyant.)
Garder les données sous forme de séries chronologiques lat et longue simplifie également l'utilisation la plus probable - où vous regarderez différentes fenêtres temporelles à différents moments - il n'est pas nécessaire de recalculer constamment un point de départ au début d'une nouvelle fenêtre temporelle en cours d'analyse.
Si les séries temporelles lat et long de chaque utilisateur ont toutes été échantillonnées aux mêmes heures exactes, comme indiqué dans une autre réponse, vous pouvez simplement concaténer les deux vecteurs de séries temporelles en un seul vecteur long. Un exemple similaire qui avait 5 séries chronologiques ressemblait à ceci:
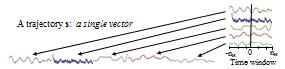 . Ensuite, vous avez un long vecteur pour chaque utilisateur que vous pouvez analyser comme tout autre vecteur pour la reconnaissance des formes, les mesures de distance, le regroupement, etc.
. Ensuite, vous avez un long vecteur pour chaque utilisateur que vous pouvez analyser comme tout autre vecteur pour la reconnaissance des formes, les mesures de distance, le regroupement, etc.
Pour les mesures de distance entre les utilisateurs, vous allez généralement utiliser un formulaire pondéré en fonction de l'application. Par exemple, lorsque vous vous concentrez sur la convergence vers une destination commune, vous augmentez le plus les poids vers la fin de la fenêtre temporelle (que vous regardiez les calculs euclidiens, la distance maximale, etc.).
Mais, la question d'origine semble dire qu'il peut y avoir différents nombres de points entre A et B pour différents utilisateurs. Et dans tous les cas, même pour le même intervalle d'échantillonnage, il est probable que les heures ne soient pas exactement les mêmes (peut-être différant d'une constante car l'échantillonnage a commencé à des moments différents). De plus, il est tout à fait possible qu'il y ait des données manquantes. Dans tous ces cas, sur le plan conceptuel, vous devez penser à chaque série chronologique sous forme continue, peut-être en y ajustant une courbe et en rééchantillonnant chaque utilisateur exactement aux mêmes moments. (C'est analogue au rééchantillonnage qui se produit dans l'analyse de photos lorsque vous réduisez une image). Vos vecteurs de séries chronologiques pour lat et long ont la même longueur et correspondent exactement aux mêmes temps,