Dans leur article sur autoencoders pour la classification texte Hinton et Salakhutdinov démontré l'intrigue produit par 2 dimensions LSA (qui est étroitement liée à la PCA): 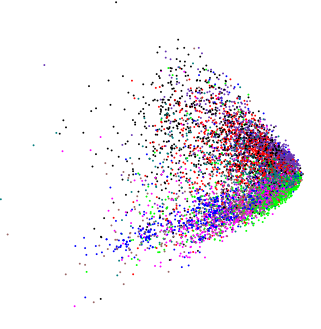 .
.
En appliquant l'ACP à des données dimensionnelles légèrement différentes, absolument différentes, j'ai obtenu un tracé similaire:  (sauf dans ce cas, je voulais vraiment savoir s'il y avait une structure interne).
(sauf dans ce cas, je voulais vraiment savoir s'il y avait une structure interne).
Si nous introduisons des données aléatoires dans PCA, nous obtenons un blob en forme de disque, donc cette forme en forme de coin n'est pas aléatoire. Cela signifie-t-il quelque chose en soi?
6
Je suppose que toutes les variables sont positives (ou non négatives) et continues? Si c'est le cas, les bords du coin ne sont que les points au-delà desquels les données deviendraient 0 / négatives. De plus, vous pouvez obtenir le même schéma que vous montrez avec des variables positives asymétriques à droite; les observations sont regroupées à l'extrémité inférieure. Si vous aviez des variables aléatoires uniformes positives, vous verriez un carré (tourné). Par conséquent, des modèles comme celui que vous montrez ne sont que des contraintes sur les données. D'autres modèles peuvent apparaître, comme un fer à cheval, mais ils ne sont pas dus à des contraintes sur les plages des variables.
—
Gavin Simpson
@GavinSimpson C'est bien plus qu'un commentaire. Pourquoi ne pas l'étendre en réponse?
—
Mike Hunter
J'ai demandé à mes enfants (3 et 4 ans) ce que ces photos leur rappellent et ils ont dit que c'était un poisson. Alors peut-être une "forme de poisson"?
—
amoeba
@GavinSimpson, merci! Dans les deux cas, les variables sont en effet non négatives, mais dans les deux cas, elles sont également à valeur entière. Est-ce que cela change quelque chose?
—
macleginn







