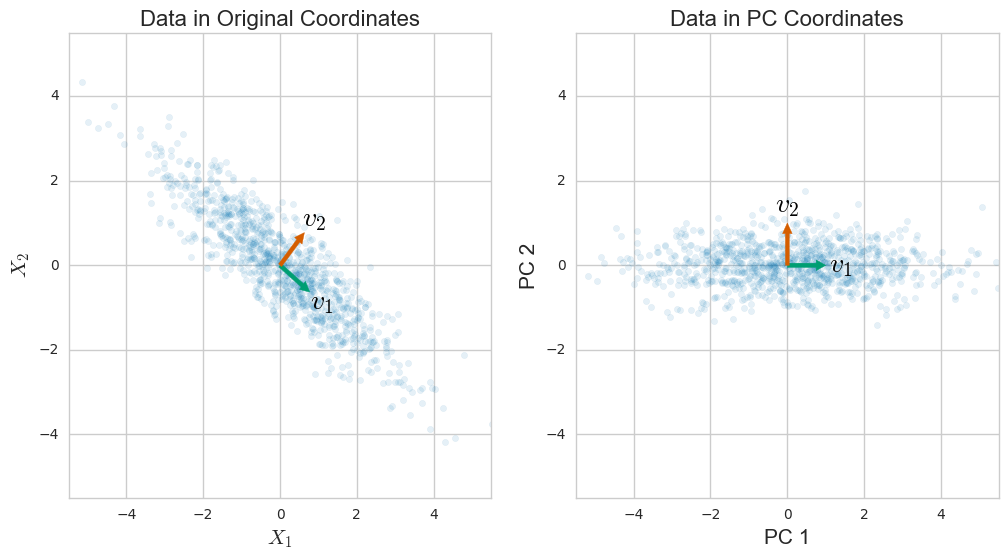
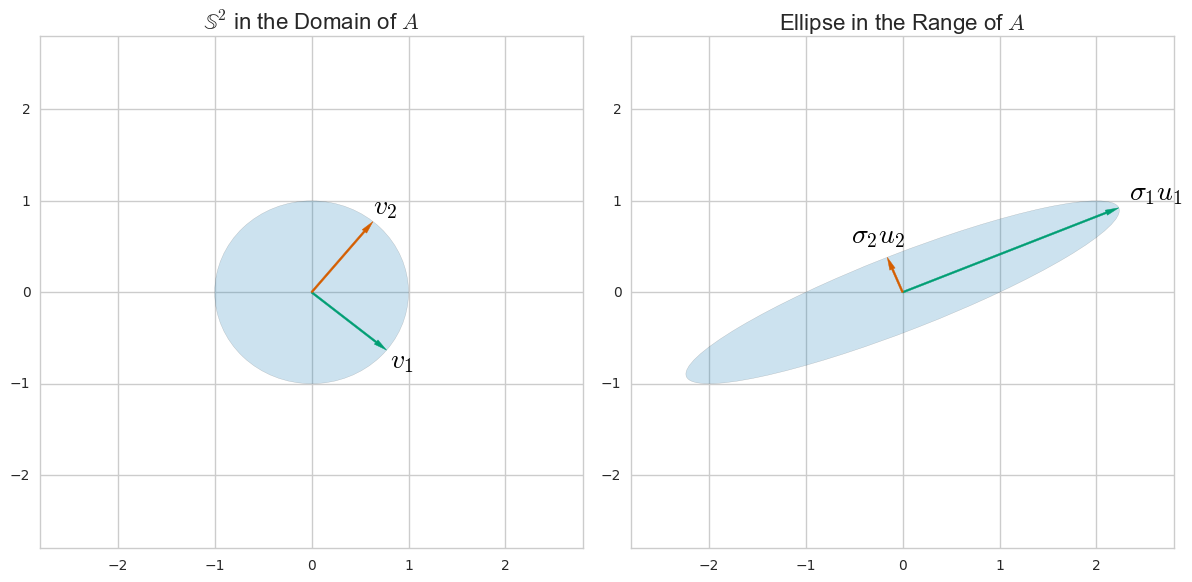
L'analyse en composantes principales (ACP) est généralement expliquée via une décomposition propre de la matrice de covariance. Toutefois, cela peut également être effectué via une décomposition en valeurs singulières (SVD) de la matrice de données . Comment ça marche? Quel est le lien entre ces deux approches? Quelle est la relation entre SVD et PCA?
Ou, en d'autres termes, comment utiliser la SVD de la matrice de données pour effectuer une réduction de dimensionnalité?
8
J'ai écrit cette question de type FAQ avec ma propre réponse, car elle est fréquemment posée sous différentes formes, mais il n'y a pas de fil conducteur, ce qui rend difficile la duplication de doublons. Veuillez fournir des méta-commentaires dans ce méta-fil d'accompagnement .
—
amibe
En plus d'une excellente réponse détaillée de l'amibe avec ses liens supplémentaires, je pourrais recommander de vérifier ceci , où PCA est considérée côte à côte avec d'autres techniques basées sur la SVD. La discussion présente l'algèbre presque identique à celle des amibes avec une différence mineure: le discours décrit en PCA la décomposition en DVD de [ou ] au lieu de - ce qui est simplement pratique car il concerne l’ACP effectuée via la composition même de la matrice de covariance. X/ √ X
—
jeudi
La PCA est un cas particulier de SVD. PCA a besoin de données normalisées, idéalement de la même unité. La matrice est nxn dans PCA.
—
Orvar Korvar
@OrvarKorvar: De quelle matrice nxn parlez-vous?
—
Cbhihe