Je viens de lire sur cyclesort via un article de blog sortvis.org. C'est probablement le plus obscur dont j'ai entendu parler jusqu'à présent, car il utilise des mathématiques que je ne connais pas (détection des cycles dans les permutations d'ensembles entiers).
Quel est le plus obscur que vous connaissez?
4
Doit revenir pour lire.
—
Mark C
Bon timing avec cela, ma classe de structures de données a juste commencé à couvrir les sortes. Maintenant, non seulement je comprends les types de base, mais aussi les plus fous.
—
Jason
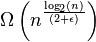 d' exécution pour ϵ > 0.
d' exécution pour ϵ > 0.