J'ai besoin de valider un nom de domaine:
google.com
stackoverflow.com
Donc, un domaine dans sa forme la plus brute - pas même un sous-domaine comme www.
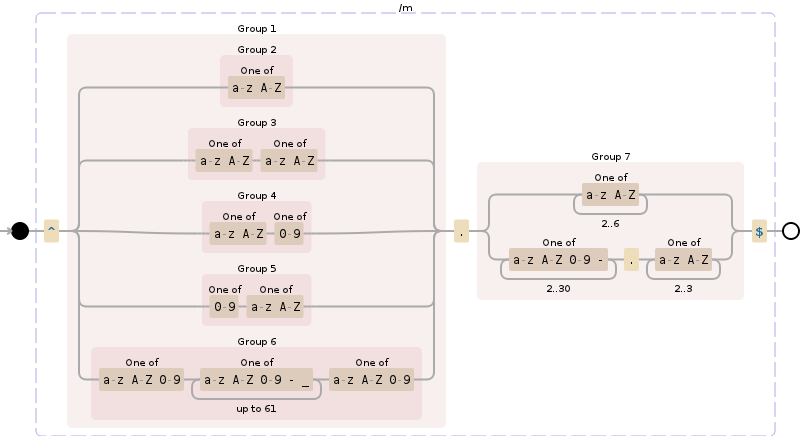
- Les caractères ne doivent être que az | AZ | 0-9 et point (.) Et tiret (-)
- La partie du nom de domaine ne doit pas commencer ou se terminer par un tiret (-) (par exemple -google-.com)
- La partie du nom de domaine doit comporter entre 1 et 63 caractères
L'extension (TLD) peut être n'importe quoi sous les règles n ° 1 pour le moment, je peux les valider par rapport à une liste plus tard, cela devrait contenir 1 ou plusieurs caractères
Edit: TLD est apparemment 2-6 caractères tel qu'il est
non. 4 révisé: le TLD devrait en fait être étiqueté "sous-domaine" car il devrait inclure des éléments comme .co.uk - j'imagine que la seule validation possible (à part la vérification par rapport à une liste) serait 'après le premier point, il devrait y en avoir un ou plus de personnages selon les règles n ° 1
Merci beaucoup, croyez-moi, j'ai essayé!
1
Peut-être pas du tout utile. En ce qui concerne google.co.uk et certains domaines japonais, je suis sûr que vous devrez réfléchir à deux fois avant d'utiliser regex pour cela. Ma pensée personnelle est que l'expression régulière n'est pas suffisante pour valider un domaine dans un domaine réel. Pour info, voici une liste presque complète des noms de domaine de deuxième niveau de tld et de code de pays: static.ayesh.me/misc/SO/tlds.txt
—
Ayesh K
Voir ma réponse à la question relative à la validation du nom d' hôte .
—
SAM
Souvent oublié: pour les noms de domaine complets, vous devez faire correspondre un point après le tld.
—
schmijos
cela fait 4 ans, maintenant le nombre est de
—
89000
Certaines de ces réponses sont plutôt bonnes, mais il y a aussi une autre bonne réponse à cette autre question qui vaut le coup d'œil.
—
craftworkgames