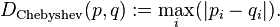TL; DR; Votre problème n'est pas lié à l'exécution de la fonction de distance. Votre problème exécute la fonction de distance tant de fois. En d'autres termes, vous avez besoin d'une optimisation algorithmique plutôt que mathématique.
[MODIFIER] Je supprime la première section de ma réponse, parce que les gens la détestent. Le titre de la question demandait des fonctions de distance alternatives avant l'édition.
Vous utilisez une fonction de distance où vous calculez la racine carrée à chaque fois. Pourtant, vous pouvez simplement remplacer cela sans utiliser la racine carrée du tout et calculer la distance au carré à la place. Cela vous fera économiser beaucoup de cycles précieux.
Distance ^ 2 = x * x + y * y;
c'est en fait une astuce courante. Mais vous devez ajuster vos calculs en conséquence. Il peut également être utilisé comme contrôle initial avant de calculer la distance réelle.
Ainsi, par exemple, au lieu de calculer la distance réelle entre deux points / sphères pour un test d'intersection, nous pouvons calculer la distance au carré à la place et comparer avec le rayon au carré au lieu du rayon.
Edit, bien après que @ Byte56 ait souligné que je n'avais pas lu la question et que vous étiez au courant de l'optimisation de la distance au carré.
Eh bien dans votre cas, malheureusement, nous sommes dans l'infographie traitant presque exclusivement de l' espace euclidien , et la distance est exactement définie comme Sqrt of Vector dot itselfdans l'espace euclidien.
La distance au carré est la meilleure approximation que vous obtiendrez (en termes de performances), je ne vois rien battre 2 multiplications, une addition et une affectation.
Vous dites donc que je ne peux pas optimiser la fonction de distance, que dois-je faire?
Votre problème n'est pas lié à l'exécution de la fonction de distance. Votre problème exécute la fonction de distance tant de fois. En d'autres termes, vous avez besoin d'une optimisation algorithmique plutôt que mathématique.
Le point est, au lieu de vérifier l'intersection du joueur avec chaque objet de la scène, chaque image. Vous pouvez facilement utiliser la cohérence spatiale à votre avantage et ne vérifier que les objets proches du joueur (les plus susceptibles de frapper / se croiser).
Cela peut être facilement fait en stockant réellement ces informations spatiales dans une structure de données de partitionnement spatial . Pour un jeu simple, je suggérerais une grille car elle est fondamentalement facile à mettre en œuvre et s'adapte bien à la scène dynamique.
Chaque cellule / boîte contient une liste d'objets que la boîte englobante de la grille contient. Et il est facile de suivre la position du joueur dans ces cellules. Et pour les calculs de distance, vous ne vérifiez que la distance du joueur avec ces objets à l'intérieur de la même cellule ou des cellules voisines au lieu de tout dans la scène.
Une approche plus compliquée consiste à utiliser BSP ou Octrees.